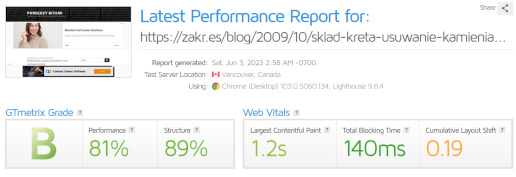
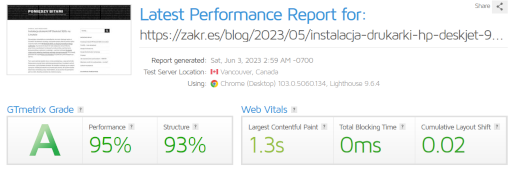
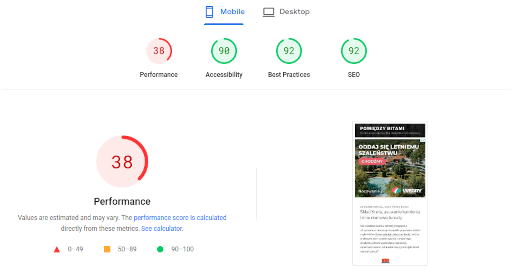
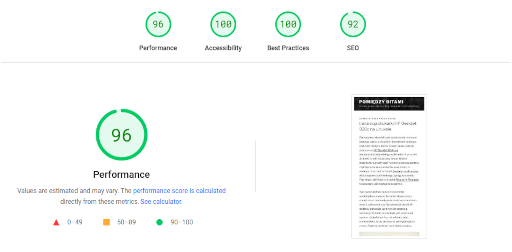
Dostałem maila od Google. Na stronie wykryto błędy, kod błędu 403. Sprawa mnie zaintrygowała. Co prawda chodziło tylko o jeden URL, ale czemu 403? Błędy 5xx czy 404 bym zrozumiał jeszcze, zwłaszcza na blogu, ale 403? Coś się tu zdecydowanie nie zgadza.
Rozpocząłem dochodzenie i zrobiło się dziwniej. Bowiem chodziło o zupełnie egzotyczny URL ( hxxps://zakr.es/tststs/ ). Na oko poprawny, ale ewidentnie tymczasowy i testowy. I zdecydowanie nie należący do bloga. W ogóle byłem zdziwiony, że Google o nim wie.
And he knows I’m right
Pierwsze co przyszło mi do głowy to robots.txt. Może dlatego, że sugerują sprawdzenie, czy dostęp nie jest tam blokowany? W każdym razie pudło. Zresztą nawet gdyby tam URL był, to raczej jako wykluczenie dla botów. A wtedy zgłaszanie braku dostępu byłoby sporą bezczelnością.
Zajrzałem do katalogu na serwerze i przypomniało mi się, że testowałem pewną rzecz. Powiedzmy, że okolice bug bounty. Tak, robienie tego na podstawowej domenie to zwykle kiepski pomysł, ale tym razem kluczowa miała być obecność naturalnego ruchu. Tak czy inaczej nic z tego nie wyszło, tj. nie udało mi się wykorzystać w planowany sposób. A katalog pozostał, choć już niewykorzystany. I nielinkowany.
Analiza
Google webmaster tools[1] pokazuje, skąd jest linkowana dana strona. W tym przypadku podał dwie strony na blogu. Jedną z konkretnym wpisem, drugą zbiorczą.
Strona odsyłająca
https://zakr.es/blog/author/rozie/page/6/
https://zakr.es/blog/2015/10/spis-wyborcow-a-rejestr-wyborcow/
Tyle, że w podglądzie źródła tego ostatniego wpisu to ja tego URLa w żaden sposób nie widzę.
Jak to wygląda czasowo? Kolejna ciekawostka to kolejne dwie daty w Google webmaster tools:
Data pierwszego wykrycia: 31.08.2022
Zapewne wtedy się bawiłem. Daty utworzenia plików potwierdzają – wszystkie pliki mają 03.08.2022. Ma to jakiś sens, tylko musiałbym zostawić pliki podlinkowane na miesiąc? Raczej niemożliwe, bo wtedy zostałyby na stałe. A nie ma. No i skąd by się wzięły w tak starym wpisie?
Ostatnie skanowanie 5 maj 2023, 11:47:16
To oczywiście możliwe, tym bardziej, że Google zauważyło błąd 403 dokładnie 3 maja 2023. Po ponad pół roku?
I’ve been talking to Google all my life
Jeśli chodzi o Google, to mamy love hate relationship. Z jednej strony doceniam firmę za GCTF, czy zabezpieczenia poczty i kont. Z drugiej strony to, co robią z prywatnością userów, nachalność reklam, tragiczny, scamerski content części reklam bąbelkowanie w wyszukiwarce i wreszcie samo bycie globalną korporacją mocno mnie odstręczają.
Ostatecznie jest tak, że umiarkowanie korzystam z ich usług. Trochę, bo wygodne, trochę, bo wypada znać. Mam webmaster tools, mam reklamy AdSense, ale tylko w wybranych miejscach. Pozwalam indeksować blog. Raczej nie korzystam z ich wyszukiwarki, tj. sięgam do niej tylko, jeśli nie znajdę wyników w podstawowej, czyli rzadko. Inne usługi Google, czyli np. Maps, Waze, translate, calendar, drive, docs – różnie, raczej korzystam, choć w ograniczonym stopniu.
Częściowe wyjaśnienie
Spojrzenie w logi serwera mówi nieco więcej:
66.249.65.223 - - [28/Aug/2022:20:35:53 +0200] "GET /tststs/ HTTP/1.1" 403 187 "-" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.79 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.70.63 - - [30/Aug/2022:20:53:52 +0200] "GET /tststs/ HTTP/1.1" 403 187 "-" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.79 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.64.227 - - [30/Apr/2023:22:32:01 +0200] "GET /tststs/ HTTP/1.1" 403 187 "-" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.5615.142 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.64.231 - - [03/May/2023:10:44:18 +0200] "GET /tststs/ HTTP/1.1" 403 187 "-" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.5615.142 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.64.229 - - [05/May/2023:11:47:16 +0200] "GET /tststs/ HTTP/1.1" 403 187 "-" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.5615.142 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
Część rzeczy się zgadza, np. wizyty kiedy Google zauważyło i zaindeksowało URL, po miesiącu od zamieszczenia plików. Widać też wizyty 03.05, kiedy sobie o nim ni stąd ni zowąd przypomniało. Mogło się też zdarzyć, że do testów wziąłem jakiś stary wpis z 2015.
Nadal nie zgadza się – albo nie mogę sobie przypomnieć – jak to się stało, że URL został na miesiąc, a nie został na stałe. I słodką tajemnicą Google pozostanie, czemu zapomniało o tym URLu na bite osiem miesięcy.
Usunąłem katalog z serwera. Może teraz Google, gdy dostanie 404, zapomni o nim na dobre?
[1] Obecnie Google Search Console, ale przywykłem do starej nazwy, więc przy niej zostanę, przynajmniej w tym wpisie.