Jakiś czas temu pisałem, że repozytorium projektu na GitHubie jest nieaktualizowane. Można było się przełączyć na pobieranie danych ze strony projektu FireHOL, ale przy niektórych zastosowaniach jest to mniej wygodne.
W komentarzach do zgłoszonego issue pojawił się link na nowy, lepszy mirror list FireHOL. Jest to stosunkowo świeże i robione przez niezależną od projektu osobę, ale LGTM i mam nadzieję, że będzie działać.
Czemu lepszy mirror? Ano dlatego, że jest parę ulepszeń, albo nawet i poprawek w stosunku do oryginału. Po pierwsze, usunięte są adresy prywatne. Usunięte są także stare blocklisty. I na koniec usunięte zostały niespójności pomiędzy plikami z sieciami i plikami z IP.
Od pewnego czasu na blogu występuje problem. Objawia się on tym, że niektóre wpisy nie wyświetlają się w całości, są jakby obcięte. Zauważyłem to parę dni temu, ale wtedy uznałem za jednorazowy wybryk i machnąłem ręką. Po części zwaliłem sprawę na cache, bo jego wyczyszczenie pomogło. Po głowie jako przyczyna chodziło mi też coś w stylu DDoS, który po publikacji artykułu na blogu uprawiają serwery Mastodon. I zupełnie nie miałem czasu na analizę.
Jednak dotarły do mnie sygnały (dzięki!) o tym, że sprawa się powtarza, postanowiłem przyjrzeć się bliżej. Dziś wszedłem z telefonu na ten sam wpis i… problem wystąpił ponownie. Z racji pory dnia ruch powinien być niewielki, więc warunki do diagnostyki powinny sprzyjać.
Trzy słowa o setupie
Blog jest dumnie wspierany przez WordPress, wykorzystywany jest nginx oraz php-fpm 8.2. Do tego dość intensywnie korzystam z wtyczek do WordPress. W szczególności do różnych optymalizacji i cache, co raczej nie ułatwi diagnostyki. Dużo elementów ruchomych, ingerencja w treść serwowanej występuje w wielu miejscach.
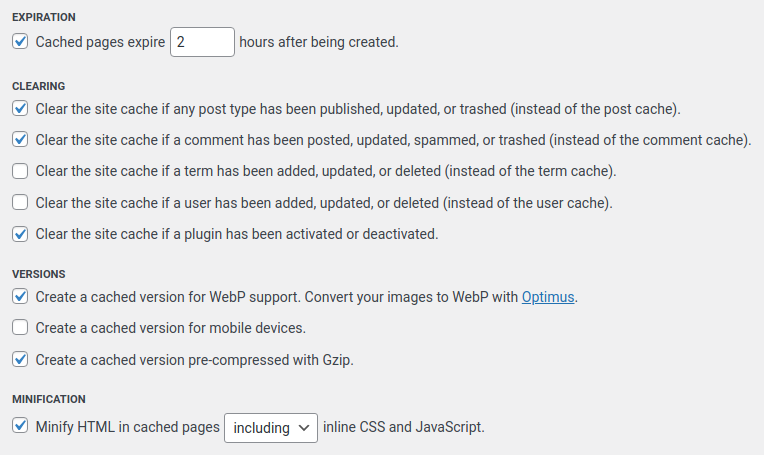
Wspomniałem o pluginie do cache jako jednym z podejrzanych. Konfiguracja Cache Enabler wygląda następująco:
W logu php-fpm nic specjalnego. Chwilę wcześniej widać raczej nie mogące mieć wpływu
[24-Sep-2023 07:44:23] WARNING: [pool www] seems busy (you may need to increase pm.start_servers, or pm.min/max_spare_servers), spawning 8 children, there are 1 idle, and 10 total children [24-Sep-2023 07:44:27] WARNING: [pool www] child 20688 exited on signal 9 (SIGKILL) after 33847.200506 seconds from start [24-Sep-2023 07:44:27] NOTICE: [pool www] child 25769 started
Diagnostyka
Problem występował na różnych przeglądarkach, także w trybie prywatnym. Zarówno na desktopie, jak i mobile. Sprawdzenie wersji zapisanej w cache pokazało, że jest ona błędna. Dobry znak, bo raczej można wykluczyć wpływ JSów. Były one podejrzane, bo wprawne oko dostrzeże, że polecenie curl przechodzi w pewnym momencie w kod źródłowy strony związany ze skryptem od statystyk Matomo.
Udało mi się ustalić, że wyczyszczenie cache pomaga, ale… tylko na pierwsze wyświetlenie. Kolejne wyświetlenia są już błędne. Sam problem występował niezależnie od obsługi JS. Czy to Firefox, czy links2, czy lynx – pierwsze wyświetlenie było poprawne, kolejne błędne.
Na pierwszy ogień poszły więc ustawienia wtyczki robiącej cache. W Minify HTML in cached pages including inline CSS and JavaScript wyłączyłem miniaturyzację CSS i JS. Nie pomogło.
Natomiast zupełne wyłączenie tej opcji jak najbardziej pomogło. Winnym okazała się zatem jedna z opcji wtyczki Cache Enabler w wersji 1.8.13. Takie tam ryzyka optymalizacji. Zgłosiłem problem na GitHub i zobaczymy co będzie dalej.
Rzuciłem jeszcze okiem na przyczynę. Prawdopodobnie chodzi o niepoprawne, zachłanne parsowanie komentarzy. Obcięcie następuje po pierwszym znaku *. Gecko/20100101 Firefox/60.0' -H $'Accept: */*' -H $'Accept-Language: en-US,en;q=0.5' natomiast linia bezpośrednio przed tym, co się zaczyna pojawiać, wygląda tak: /* tracker methods like "setCustomDimension" should be called before "trackPageView" */
I tak sobie radośnie aktualizacje leżą od blisko dwóch miesięcy. To może nie być po prostu dłuższy urlop…
W każdym razie, jeśli ktoś korzysta z powyższych list i zależy mu na aktualizacjach, to polecam przepiąć się na wersję bezpośrednio ze strony projektu. Dostępnej pod linkiem download local copy dla każdej z list. Te są aktualizowane.
I tak to się w tym IT/security kręci…
UPDATE: To nie jest tak, że powstał ten wpis i over. Założyłem kolejne issue, na wypadek gdyby autor przeoczył wcześniejsze. Napisałem też maila. Póki co cisza.