
Tytułem wstępu: Google ma swoją chmurę, czyli Google Cloud Platform, a w ramach niej coś takiego jak free tier, czyli zasoby dostępne bez opłat[1]. Zasoby są niewielkie, dodatkowo podlegające pewnym ograniczeniom, raczej do zabawy. Ale do testów, nauki czy właśnie zabawy – idealne. Między innymi można mieć uruchomioną w ramach compute engine najsłabszą VMkę, czyli f1-micro.
Jeśli ktoś korzysta z GCP, to zapewne dostał już maila. Dla tych, co maila przeoczyli, krótkie podsumowanie. Od pierwszego sierpnia 2021 instancje e2-micro są bezpłatne (w określonej ilości czasu), natomiast od pierwszego września instancje f1-micro będą płatne. Regiony pozostają bez zmian. Instrukcja zmiany linkowana w mailu dostępna jest tu.
To różne platformy, więc ciężko porównać dokładnie, ale:
f1-micro to 0.2 VCPU i 0.6 GB RAM w cenie $0.0076 (us-central1)
e2-micro to 0.25 VCPU i 1 GB RAM w cenie $0.008376 (us-central1)
Dodatkowo w przypadku e2-micro możliwy jest burst do 2 VCPU.
Google pisze[2]:
As we improve the experience of the Free Tier, we will be introducing the E2-micro VM, which is a part of a second generation VM family.
Wydajność
W przypadku RAM zysk jest oczywisty, natomiast w przypadku CPU – niekoniecznie. Wiele zależy od tego, na jakiej platformie CPU znajduje się obecnie VMka, i na jakiej wyląduje po przeniesieniu. Tabela platform CPU dla serii N1 i E2 jest dość skomplikowana. Jednak patrząc na base frequency, przeciętnie powinno być szybciej.
I jeszcze wynik cat /proc/cpuinfo z mojej instancji f1-micro:
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 63
model name : Intel(R) Xeon(R) CPU @ 2.30GHz
stepping : 0
microcode : 0x1
cpu MHz : 2299.998
cache size : 46080 KB
physical id : 0
siblings : 1
core id : 0
cpu cores : 1
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology n$
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs
bogomips : 4599.99
clflush size : 64
Jak się zmigruję to uzupełnię wpis, co dostałem po migracji i jak wrażenia.
Migracja
Wczoraj zmigrowałem maszynę na e2-micro. Migracja błyskawiczna i bezproblemowa. Zgodnie z instrukcją zatrzymać instancję, wyedytować typ, zapisać zmianę, uruchomić maszynę.
Po migracji dostałem dokładnie ten sam procesor. Tyle, że teraz cat /proc/cpuinfo pokazuje dwa. Jeśli chodzi o osiągi i wydajność w praktyce, to najlepiej widać to na obrazku.
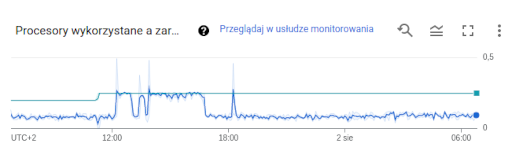
Migracja chwilę przed 12:00, później wzrost obciążenia spowodowany porządkami, chwilę po 18:00 koniec ostatnich ręcznych prac. Jak widać, główny zysk wynika ze wzrostu mnożnika z 0.2 do 0.25 VCPU. Ponieważ przydział jest dynamiczny, procesy jednowątkowe także skorzystają na zmianie parametrów.
Podsumowując, warto migrować, bo e2-micro w stosunku do f1-micro oferuje 66% więcej RAM i 25% więcej CPU.
[1] Wymagane jest podpięcie karty debetowej, a po przekroczeniu puli darmowych zasobów jest automatycznie naliczana opłata za przekroczoną część.
[2] Nawiasem, wysłaniem tego maila Google Cloud Platform zdobyło u mnie sporo punktów sympatii. Mogli przecież np. zamieścić info o zmianie cenników free tier na blogu i billować nieuważnych, albo wysłać suchego maila o zmianach w cenniku. Wiele firm tak właśnie by postąpiło. A tu osobne, czytelne powiadomienie, z instrukcją migracji. Miło.