
Apple jest nachalne do niemożliwości. Nie gonię za najnowszymi wersjami macOS, raczej jestem oczko z tyłu. Tak naprawdę jeśli chodzi o funkcjonalności, to rzadko widzę różnicę, a mój support techniczny zwykle ostrzega przed problemami i raczej zaleca poczekać z aktualizacją. W takiej sytuacji nie ma się co spieszyć. W końcu nawet Sonoma jest jeszcze normalnie wspierana.
Tymczasem korzystam z wersji Sequoia. O aktualizacji nie pisałem, bo nudna i niczego nie wniosła wg mnie. Z godnych pamięci szczegółów – długie pobieranie (jakieś 2h na 100 Mbps), za to krótki downtime – obrócił poniżej 30 minut ze wszystkim.
Chciałbym nadal korzystać z Sequoia, ale Apple uparło się, że wciśnie mi Tahoe. Nie drzwiami, to oknem. Po pierwsze, popup, że jest nowa wersja. Co mogę wybrać? Albo aktualizację do Tahoe w nocy, albo że przypomni później[1]. Opcji sam zadecyduję, kiedy zechcę zaktualizować, nie przypominaj więcej nie ma. Liczą na missclick?
Daleko idący wniosek z tym missclickiem? No nie wiem, bo jak wejdę w Software Update to mam u góry aktualizację do Tahoe, a poniżej inne aktualizacje (Also available), które wyglądają tak:
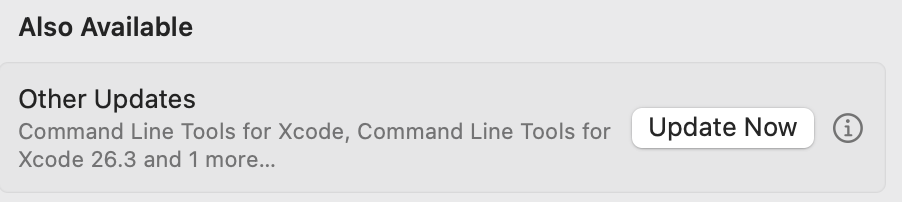
Bezpiecznie? No nie wiem, bo kliknięcie znaczka z informacją pokazuje:
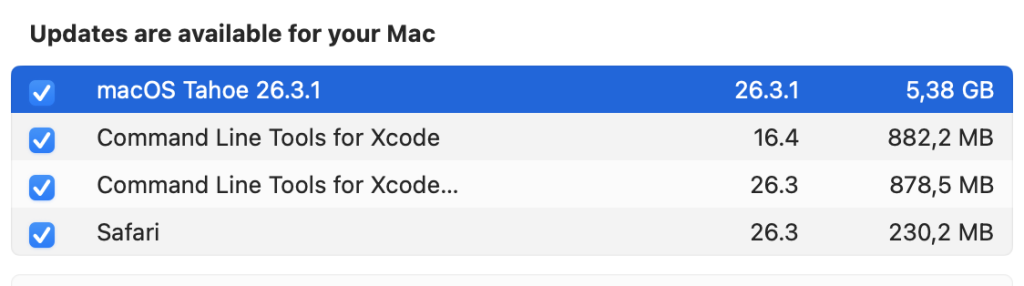
Znaczy znowu wciskają Tahoe. Zapewne można odznaczyć, ale jeśli jesteście przywiązani do Sequoi i chcecie uniknąć aktualizacji do Tahoe, bądźcie czujni.
Oczywiście nie jest to nic nowego, Microsoft robił podobnie wymuszając przejście z Windows 7 na 10.
Dla jasności, co do zasady uważam, że przypominanie o aktualizacjach jest dobre, aktualizacje automatyczne też. Ale niekoniecznie podoba mi się takie nachalne wciskanie nowej wersji systemu. Szczególnie, gdy stary jest wspieramy. To jednak grubsza i potencjalnie inwazyjna zmiana.
[1] Nie jest określane, kiedy nastąpi później. W zasadzie mogłoby wyskakiwać co godzinę.