W wielu miejscach ludzie narzekają, że Google zmieniło algorytmy, ich strony spadły w rankingu, choć stosowali się do zaleceń Google, a biznes upada. To oczywiście smutne, tylko nie do końca widzę w tym winę Google. Oparcie biznesu o jednego partnera było świadomą decyzją. Stosowanie się do zaleceń Google w sprawach SEO nigdy nie dawało gwarancji, że zawsze będzie dobrze, prawda? Gwarancji, że te zalecenia się nie zmienią też nie było. Gdyby tylko w jakiś sposób dało się przewidzieć, że gigant będzie kierował się wyłącznie własnym zyskiem…
Zmiany i błędy
Błędy się zdarzają. Zmiany też. Uzależnianie się od jednego dostawcy zawsze jest poważnym ryzykiem. Nawet, jeśli dostawca wydaje się duży i solidny[1]. Zresztą, akurat Google od dawna pokazuje apetyt na to, by korzystać z czyjegoś dorobku, niekoniecznie dzieląc się zyskiem. Pamiętacie Accelerated Mobile Pages? Już wtedy twórcy treści narzekali, że ruch klientów nie trafia do nich i tracą zyski z reklam. Reklam Google, oczywiście. No ale skoro Google mogło dostarczyć ludziom wynik wyszukiwania AKA content, w dodatku od siebie, to po co miałoby przekierowywać klienta na źródło i płacić za wyświetlenia/kliknięcia w reklamy? A jeszcze osoba, która szukała gotowa dodać stronę do bookmarków i nie skorzystać następnym razem z wyszukiwarki, gdzie Google może mu wyświetlić reklamy w wynikach wyszukiwania… No czysta strata przecież.
Błędy zdarzają się i grubszego kalibru, nawet przy płatnych usługach. Bo indeksowanie i pokazywanie w wyszukiwarce jest bezpłatne i bez żadnych dwustronnych umów i gwarancji. A przecież zdarzyło się zablokowanie i usunięcie usług, za które płacono. Oczywiście z danymi[3].
AI
Przeżywamy właśnie zachłyśnięcie się AI[2], które pakowane jest dosłownie wszędzie. Czy ma to sens, czy nie. Jest to symbol/synonim nowoczesności, więc pewne było, że wyniki wyszukiwania też będą to wykorzystywać. Zresztą, Bing zrobił to już dawno. Głośno robi się o błędach wyszukiwarek opartych o AI. Oczywiście, takie błędy są. I pewnie będą, szczególnie, że wiemy, że LLMy lubią halucynować. Ale… w tradycyjnych wyszukiwaniach też były. Tylko po prostu nikt raczej nie robił afery, gdy link był nieadekwatny czy zawierał błędne informacje. No chyba, że w wynikach wyszukiwania, tłumaczenia albo na Google Maps znalazło się coś godzącego w znaną osobę lub instytucję. Wtedy było trochę śmiechu i szybka korekta. I jakoś nikt nie robił afery.
W sumie zastanawiam się, kiedy do ludzi dotrze, że LLMy są niezłe odtwórczo, ale niespecjalnie są w stanie coś nowego wymyślić. I tak naprawdę żerują na tym, co ludzie wymyślili wcześniej. I bez dostępu do tych danych są niczym. Można obserwować bunt twórców treści w serwisie Stack Overflow. Ciekawe kiedy powstanie zdecentralizowana, szanująca autorów alternatywa…
Zmiany algorytmów Google
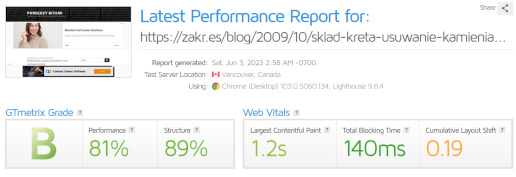
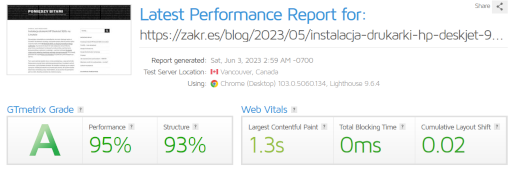
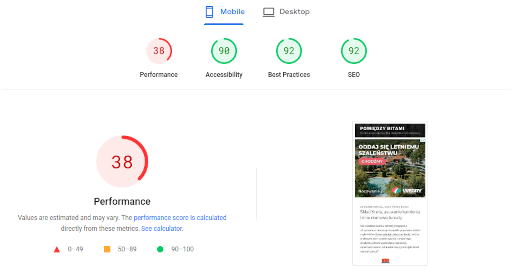
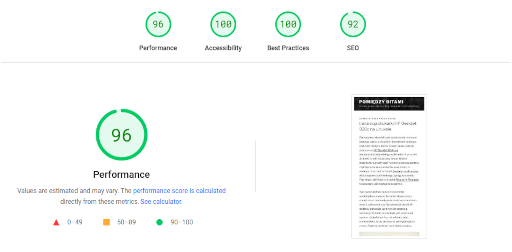
Dla jasności – sam obserwuję zmiany algorytmów w Google u siebie na blogach. Pozycje i liczby odsłon w Google webmaster tools zmieniły się istotnie, liczba wejść – mierzona niezależnie – spadła. Też istotnie. Wszystko to zaczęło się w ostatniej dekadzie kwietnia 2024. Odnotowuję z kronikarskiego obowiązku, bo nie ma to dla mnie żadnego znaczenia. I po części pewnie kwestia pogody.
Wyszukiwarki
I na zakończenie nie całkiem nie na temat: DuckDuckGo nie działało podczas awarii Bing. Wiedziałem, że korzystają z ich wyników (od czasu rozwiązania/zawieszenia współpracy z Yandex – chyba już tylko z nich), ale w obecnej sytuacji poszukam jakiejś alternatywy dla podstawowej wyszukiwarki. Świata to nie zmieni, bo i tak jestem multiwyszukiwarkowy – często sprawdzam wyniki w 2-3, poza tym, na różnych komputerach mam różną domyślną, ale spróbować można. Póki co silnym typem jest Qwant – działający na europejskich, bardziej sprzyjających prywatności, zasadach.
[1] A może „zwłaszcza”? Jak głosił slogan z pewnej reklamy duży może więcej. Podmioty o dużym udziale na rynku będą miały tendencję do monopolu/oligopolu, bo taki jest naturalny trend ekonomiczny. A że monopol nie służy klientom, to wiemy. Pytanie tylko czy i kiedy taki duży dostawca zechce skorzystać ze swojej pozycji.
[2] Gdzie chwilowo AI = LLM, co do prawdziwej sztucznej inteligencji ma się nijak.
[3] Już po opublikowaniu tego wpisu Google zamieściło oficjalne stanowisko w tej sprawie. Są pewne rozbieżności, np. podobno backupy nie zostały usunięte. Ale mimo to do przywrócenia wykorzystano zewnętrzne backupy. Hm!
UPDATE: Dodany link do stanowiska Google w sprawie usunięcia usług.