
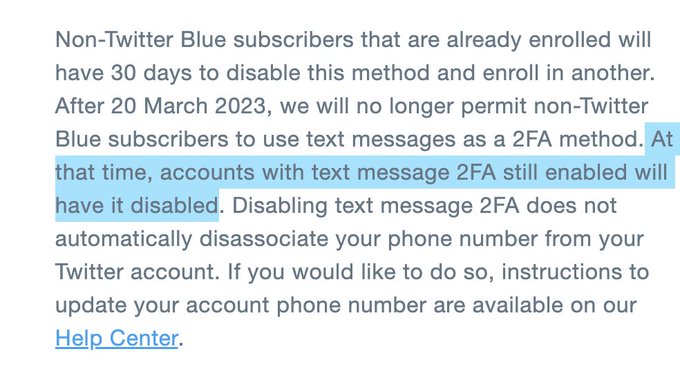
Przepraszam za clickbaitowy tytuł, ale tak podobno zostały odebrane ostatnie działania i wiadomości wysyłane przez ten serwis. Zatem, gwoli ścisłości nie 2FA, tylko jedną z metod 2FA (SMS) i nie wyłącza, a udostępnia jedynie w płatnej wersji usługi. Nadal można mieć na Twitterze 2FA, za darmo, w dodatku w teoretycznie bezpieczniejszej wersji.
Motywacja jest oczywista. Chodzi o pieniądze. Wszyscy się przyzwyczailiśmy, że SMSy są darmowe, w pakiecie lub abonamencie. Bo taka jest rzeczywistość, przynajmniej w Polsce i dla SMSów wysyłanych w kraju. Tyle, że sytuacja z puntku widzenia serwisu internetowego wygląda nieco inaczej – korzystają z zewnętrznych dostawców, wysyłają do różnych krajów. To jest usługa, która kosztuje i to zapewne niemało. Czyli SMSy to taki rodzaj 2FA, gdzie całość kosztu ponosi serwis. No chyba, że przerzuci ten koszt na użytkownika, co Twitter właśnie zrobił.
Przy okazji, SMSy to jeden z najsłabszych rodzajów 2FA. Dla przeciętnego użytkownika Twittera być może nie ma to praktycznego znaczenia[1], ale istnieją ataki pozwalające na obejście tej metody komunikacji. Jak widać były w praktyce stosowane, także do przejmowania kont na Twitterze. Co gorsza, ofiara, czyli właściciel konta z takim 2FA praktycznie nie ma wpływu na skuteczność tych ataków. Atak odbywa się bowiem na dostawcę sieci komórkowej, a w zasadzie na jego pracowników obsługi klienta.
Dygresja: jeśli korzystamy z serwisu na telefonie i odbieramy SMS służące do 2FA na tym samym telefonie, to czy to jest jeszcze drugi składnik zaczyna być mocno dyskusyjne. Zależy od zagrożenia, przed którym chcemy się bronić. Dla kradzieży hasła czy sesji np. przez XSS wystarczy, dla malware na telefonie czy kradzieży telefonu – niekoniecznie. Dotyczy to także innych metod 2FA, jak email czy TOTP w Google Authenicator[2] czy aplikacji.
Niezależnie od motywacji, zapewne przypadkiem, Twitter został pionierem rewolucji w security na miarę walki Orange ze spamem przez zablokowanie wysyłki maili na porcie 25. Jest to pierwszy duży serwis, który odsyła przestarzałe 2FA via SMS tam, gdzie jego miejsce. Tj. do fanaberii typu papierowa faktura w usługach masowych. Tu od dawna mamy mniej lub bardziej zawoalowane opłaty za wystawianie papierowych faktur. Zwykle w formie „będzie 5 zł taniej, warunkiem skorzystania z promocji jest wyrażenie zgody na faktury elektroniczne”. I jakoś nikt z tym nie ma problemu. Chociaż faktury elektroniczne są także tańsze dla firm. Ale lepsze, bo nie marnujemy papieru i środków na jego transport.
Jeśli ktoś chce nadal korzystać za darmo z 2FA dla konta na Twitterze, to nadal ma dostępne takie opcje:

Według mnie marginalizacja 2FA via SMS to dobra zmiana i będę kibicował innym serwisom, które się zdecydują na jej wprowadzenie. O wadach i zaletach poszczególnych metod 2FA może napiszę innym razem.
[1] Przykro mi, nikomu nie zależy na przejęciu naszych kont. A przynajmniej nie jest to warte ryzyka i/lub kilkuset złotych.
[2] Upraszczam, nie tylko Google Authenticator to oferuje. Tak naprawdę to trywialny algorytm, ale ta implementacja jest najbardziej znana i chyba najpopularniejsza.