Piekło zamarzło. Przedwczoraj na blogu ogłoszono, że Google Authenticator dorobił się backupu kodów na koncie Google. Wersja oferująca tę funkcjonalność jest już do pobrania z Google Play. To duża i ważna zmiana i okazja do notki. Przy okazji zmieniła się niestety ikona programu.
Jak działa TOTP?
Zasada działania TOTP (Time-based One-Time Passwords) jest bardzo prosta, a implementacja w większości języków to kilka-kilkanaście linii kodu. W skrócie: najpierw, przy włączaniu tej metody uwierzytelniania, serwer generuje i zapisuje sekret. Dzieli się nim z użytkownikiem, zwykle przy pomocy QRcode.
Od tej pory kody są generowane na podstawie bieżącego czasu (unix timestamp), zaokrąglonego do 30 lub 60 sekund, oraz ww. sekretu. Najpierw są hashowane, następnie hash jest przekształcany na sześciocyfrowy kod. I już.
Jak widać, do generowania kodów dla danego użytkownika wystarczy poznać sekret. Natomiast z uwagi na użycie funkcji skrótu, odtworzenie sekretu z kodu jest bardzo trudne. Sprytne.
Znaczenie
Czemu to takie ważne? Brak jasnego, prostego sposobu backupów był dla mnie ogromnym argumentem przeciw korzystaniu z TOTP. Stosunkowo łatwo było stracić dostęp do kodów, czyli odciąć się od serwisu. A dostępność jest przecież składową bezpieczeństwa. Dlatego wolałem jako 2FA wykorzystywać kody SMS. Mocno niedoskonałe: drogie, niewygodne, zawodne, podatne na ataki. Oczywiście koszt jest po stronie serwisu, który musi wysyłać kody. Wygoda to rzecz dyskusyjna, niektórzy dostawcy nawet nie mieli dużego opóźnienia w dostarczaniu SMSów. Awarie operatorów nie zdarzały się często, a SIM swap nie jest tanim czy łatwym atakiem.
Oczywiście istniały alternatywne aplikacje, które oferowały backup sekretów. Tylko jakoś bardziej ufam dostawcy systemu operacyjnego na moje urządzenie, niż losowej appce. Podejrzewam, że ludzi takich jak ja było więcej.
Jak było wcześniej?
Wcześniej było… słabo. Z backupem Google Authenticator można było sobie radzić na kilka sposobów. Pierwszym było zdjęcie/screenshot QRcode przy włączaniu TOTP. Średnio wygodne w przechowywaniu (bitmapa/wydruk), zajmujące dużo miejsca, żeby wyszukiwać trzeba dobrze opisać.
Kolejny sposób to zapisanie kodów ratunkowych. Większość serwisów w momencie generowania sekretu TOTP podaje kody ratunkowe do wydrukowania/zapisania. Niezłe, o ile ktoś korzysta z managera haseł.
Ostatni sposób to… drugie urządzenie z Google Authenticator i utrzymywanie kodów na obu urządzeniach. Dość drogie z uwagi na koszt kolejnego urządzenia, niezbyt wygodne z uwagi na konieczność ręcznej synchronizacji.
Jak widać, powyższe sposoby są niezbyt wygodne, albo działają dla osób, które mają dobrze poukładane backupy. Dla osób, które po prostu chcą mieć zabezpieczone konta przez 2FA, a niekoniecznie chcą projektować system backupów, uwzględniając jego dostępność – bardzo średnie. Bo właśnie, fajnie, że masz wydrukowane QRcode’y czy kody ratunkowe przechowywane w sejfie. Ale co jesteś właśnie na wakacjach i tracisz telefon, wraz z dostępem do wszystkich serwisów?
Wady
Obecne rozwiązanie nie jest idealne. Nadal będziemy uzależnieni od Google w kwestii backupu kodów i ich odzyskania. Dla większości ludzi będzie to zapewne akceptowalne ryzyko, tym bardziej, że ma znaczenie wyłącznie przy odzyskiwaniu, czyli bardzo rzadko.
Kolejną wadą jest trzymanie wszystkich jajek w jednym miejscu. Konto Google staje się SPOF. Szczególnie, jeśli ktoś korzysta także z zapamiętywania haseł przy pomocy Google.
Jeszcze osobną sprawą jest kwestia zaufania do samego Google. Nie napisałem tego pierwotnie i wprost, ale uznałem, że jeśli mamy OS od Google, zintegrowany z ich sklepem i konto w ich serwisie, to z jakiegoś powodu ufamy Google. Zależy oczywiście od modelu zagrożeń.
Zaufanie do Google jest tym istotniejsze, że backup kodów trafia do Google w postaci niezaszyfrowanej. Czy Google udostępni np. służbom kody 2FA? Nie wiem, ale się domyślam. Po raz kolejny, kwestia modelu zagrożeń. Szczęśliwie Google zapowiedziało dodanie szyfrowania.
Podsumowanie
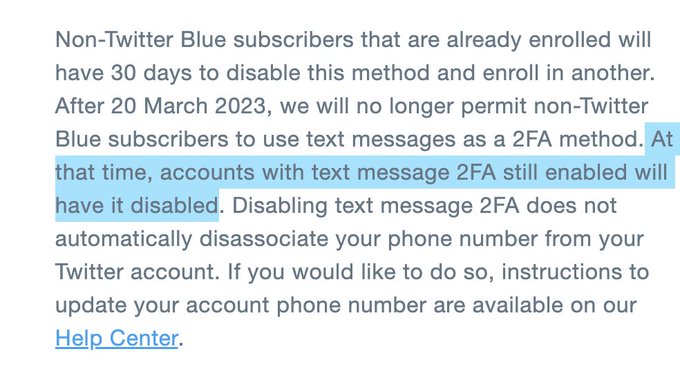
Uważam tę zmianę za bardzo dobrą, z punktu widzenia przeciętnego użytkownika i mam nadzieję, że przyczyni się do popularyzacji 2FA. W ogóle ostatnio mamy dobry klimat dla 2FA opartych o TOTP. Najpierw wyłączenie 2FA przy pomocy SMSów w Twitterze, teraz backupy w Google Authenticator.
Paradoksalnie jednak, po tej zmianie może się okazać, że… lepiej zmienić dostawcę appki do 2FA, niż włączać backup do chmury Google w Google Authenticator. W sugerowanych pojawiły się FreeOTP, FreeOTP+, 2FAS.
UPDATE: Dodane info o zaufaniu do Google. Dodane info o braku szyfrowania i zapowiedź dodania. Zaktualizowane podsumowanie.