Jakiś czas temu skusiłem się na Empik Premium. Co prawda z cashback Empik się wycofał, ale nadal uważam, że w sumie warto, bo głównie o dostęp do audiobooków w ramach Empik Go mi chodziło. W każdym razie 50 zł[1] za rok wydawało się niewygórowane. I choć mam wrażenie, że na początku dostępnych było więcej tytułów, to nadal uważam, że to fajna opcja.
W każdym razie szukałem jakiegoś audiobooka do posłuchania na Empik Go. Jakoś padło na Płomień i krzyż autorstwa Jacka Piekary. Niczego tego autora nie znałem, choć nazwisko kojarzyłem. Polska fantastyka, ilość tytułów, ocena w okolicy 4 i do tego opowiadania nie nastrajały zbyt optymistycznie. Jednak stwierdziłem, że dam szansę. Pozytywne zaskoczenie: lekko się czyta (słucha!), ciekawy pomysł i na dobrą sprawę, z uwagi na powiązania, spokojnie można uznać te niby opowiadania za kolejne rozdziały powieści.
Disclaimer po rozmowie ze znajomymi: nie zwracałbym większej uwagi na krótkie opisy traktujące o alternatywnej historii w religii. Tzn. to jak najbardziej ma miejsce, ale – przynajmniej z tego co dotychczas czytałem – jest bardziej tłem zdarzeń, nie ich osią.
Jestem po lekturze tomu pierwszego[2] i wyrażam umiarkowany zachwyt. Intryga zgrabnie się rozwija, jeśli w kolejnych tomach będzie utrzymany poziom, to gdzie jest serial, ja się pytam? Bo z tego co do tej pory poznałem, to aż się prosi o ekranizację.
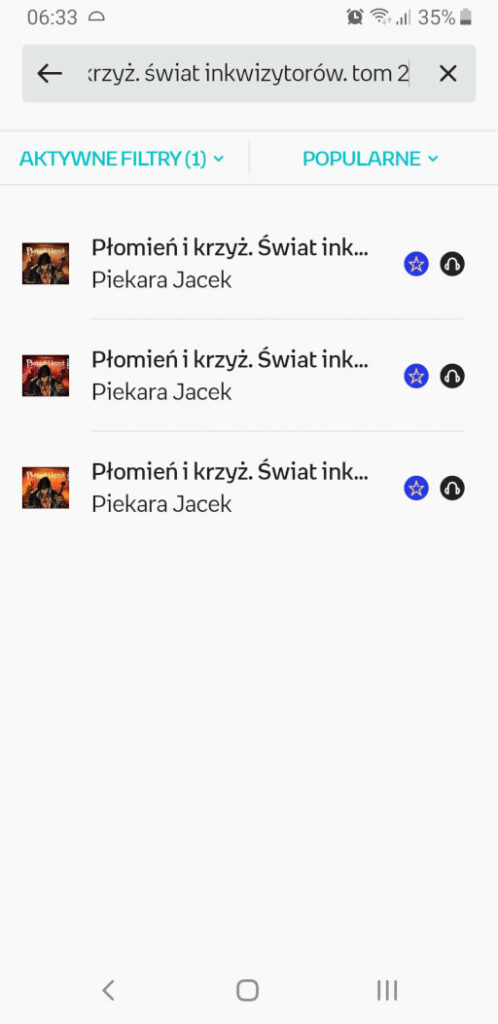
I jeszcze taka zabawna sytuacja. W polu wyszukiwania w Empik Go wpisałem płomień i krzyż, wybrałem tom drugi z podpowiedzi, zatwierdziłem wyszukanie i ujrzałem coś takiego:
Wyszukiwanie tomu II w Empik Go, smartfon Android
Pytania konkursowe (nagród nie przewiduję, ale konkurs może być, prawda?):
Co kryją poszczególne pozycje?
Którą z pozycji należy wybrać, aby otworzyć wyszukiwany tom 2?
Co się stanie po zmianie położenia smartfona z prezentowanego na poziome?
Rozwiązanie za jakiś tydzień w formie aktualizacji wpisu. Podpowiem tylko, że kto w IT pracuje, ten w cyrku się nie śmieje.
UPDATE Pora na nieco spóźnione rozwiązanie zagadki.
Są to kolejne trzy tomy cyklu. Skoro wyszukuję tom 2 to pewnie jestem zainteresowany także 1 i 3. Logiczne.
Nie wiem. Trzeba próbować. Ale jest pozytyw: po powrocie pozycje się nie zmieniają, więc czekają nas najwyżej trzy próby.
Nic. Skoro se user przechyla smartfona, to chce oglądać ekran bokiem, a ustawienia systemowe kłamią. Oczywiste.
[1] Świta mi, że wtedy było 40 zł. Nieistotne w sumie, historii płatności sprawdzać nie będę. [2] Przynajmniej wg Biblionetki bo wg Wikipedii wygląda nieco inaczej. W każdym razie niczego nie brakuje i wszystko się spina.
UPDATE Jakoś rok później dotarłem do końca, przynajmniej istniejących pozycji. Czyli przeczytałem Przeklęte przeznaczenie. Jak miałem wrażenie w pewnym momencie, że robi się nieco wtórnie, tak ta pozycja mi się bardzo podobała. Z posłowia można dowiedzieć się, że powstaje gra oraz coś filmowego się dzieje. I bardzo to cieszy.
Niedawno usłyszałem pytanie o setup dla abcc, które zawierało ciekawy element – jedno z dostępnych połączeń było przez USB[1]. Zaintrygowało mnie to, bo tak się złożyło, że zupełnie nie znałem tematu. Zawsze udostępniałem internet z Androida wykorzystując WiFi i tworząc access point. Nie byłem pewien jak takie połączenie w ogóle jest widoczne pod Linuksem.
Poczytałem, sprawdziłem i sprawa jest prosta. Aby udostępnić internet z telefonu z Androidem należy najpierw podłączyć kabel USB. Dopiero wtedy aktywna staje się opcja USB tethering. Po jej aktywacji na telefonie, w systemie powinno pojawić się urządzenie usb0. Traktujemy jak zwykłą przewodową kartę sieciową.
Takie proste, a nigdy nie korzystałem. Czy warto udostępniać połączenie z Androida po USB, zamiast po WiFi? Jedna zaleta jest oczywista – podczas udostępniania połączenia telefon zużywa więcej prądu. Podłączenie kablem do komputera zapewnia od razu ładowanie. Z kolei oczywista wada to mniejsza swoboda ruchów – kabel jest zawsze jakimś ograniczeniem.
Pora sprawdzić wydajność. Szybki zgrubny test, po prostu fast.com, w dodatku pojedynczy pomiar dla każdej konfiguracji.
Operator nr 1 42 Mbps download 10 Mbps upload, latency 32 ms unloaded, 462 ms loaded na WiFi 2,4 GHz 42 Mbps download 15 Mbps upload latency 30 ms unloaded, 420 ms loaded na USB
Operator nr 2 (IPv6) 78 Mbps download 11 Mbps upload, latency 30 ms unloaded 321 ms loaded na WiFi 5 GHz 71 Mbps download 14 Mbps upload, latency 28 ms unloaded 446 ms loaded na USB
Wielkich różnic jak widać nie ma. Wariancie optymistycznym, czyli nieobciążonym łączu na kablu zyskamy nieco na opóźnieniach sieciowych. Lepsze powinien też być upload. Czyli domyślnie warto podłączyć kabel USB. Nie są to jednak wielkie różnice, więc jeśli nie gramy w gry online albo nie zależy nam na prędkości uploadu, wygląda, że może decydować wygoda.
UPDATE I jeszcze dla porównania wyniki z mojej kablówki, nominalnie 60/10: 62 Mbps download 7 Mbps upload, latency 6 ms unloaded 50 ms loaded na WiFi 5 GHz
Oczywiście inny serwer, pomiar dzień później itd. Ale i tak widać, jak bardzo LTE dogoniło, albo wręcz przegoniło kablówkę opartą o miedź. Światłowód zapowiadany był dwa lata temu, ale nadal nic nie wskazuje, by miał się pojawić.
[1] Sprawa w toku, może zasłuży na osobny wpis jak skończę.
Szczeżuja namawiał, namawiał i w końcunamówił. Znaczy nie namawiał wprost, ale pisał o zaletach fediwersum i jakoś tak mnie zachęcił do założenia konta Mastodon[1]. Nie żeby trzeba było mnie specjalnie namawiać, bo od zawsze miałem słabość do alternatywnych rozwiązań i DIY. Nawet od dłuższego czasu produkcyjnie jest w użyciu Diaspora*.
Geneza
Czemu w ogóle wziąłem się za Mastodona, skoro jest Diaspora*, której używam od kilku lat? To, że Diaspora to niby bardziej Twitter, a Mastodon to niby bardziej Facebook nie miało znaczenia. Zresztą piszę „niby bardziej”, bo odnoszę dokładnie odwrotne wrażenie. Możliwe, że kwestia mojej instancji Mastodona, która limituje ilość znaków we wpisie do 500. Nie żeby mnie to jakoś bolało, ale Diaspora* chyba nie limituje. Przynajmniej nie zauważyłem. No ale może znowu może to być kwestia konkretnej instancji.
Poza tym, że lubię testować nowe rzeczy, poszło o ideę fediwersum i chęć sprawdzenia jak to działa w praktyce. Diaspora* niby umożliwia wymianę z innymi instancjami, ale robi to swoim własnym protokołem. Niespecjalnie przez coś innego używanym, jak zeznaje anglojęzyczna Wikipedia. Były plany implementacji Activity Pub, ale zostały porzucone. Brak wsparcia standardu Activity Pub źle wróży na przyszłość. No i nie ma tak ciekawych implementacji jak Pleroma, czyli własny serwer, który można uruchomić na Raspberry Pi.
Propozycja logo fediwersum. Tęczowy pentagram. Szatan gender. Gównoburza za 3…2…1… Źródło: https://en.wikipedia.org/wiki/Fediverse#/media/File:Fediverse_logo_proposal.svg
Pozytywy
Jednak miało być o Mastodonie. Na początek dobre wiadomości. Coś jest i nawet działa. Nie jest to wielkie zaskoczenie, bo Diaspora* działała lata temu. Rejstracja konta na wybranej instancji trwała moment. W przeglądarce WWW jest OK i używalnie. Na mobilki są aplikacje. Jako klienta na Androida wybrałem Tusky, czyli jeden z popularniejszych klientów. Daje radę. I chyba nawet wygodniej mi się przegląda, czyli czyta, niż przez WWW.
Kolejny pozytywny aspekt – jest jakieś życie. Są ludzie, nawet dość regularnie piszą. I pisząc ludzi mam na myśli ludzi, nie konta, na których zapięty jest jakiś bot czyli automatyczny feed.
Są integracje. Na przykład WordPress ma wtyczki, które pozwalają zamieszczać informacje o nowych wpisach na Mastodon[3]. W przypadku Twittera korzystam do tego z 3rd party serwisu, a na niszowego Blablera sam dopisałem stosowny skrypt.
Sama platforma też generalnie działa i nie zauważyłem problemów z korzystaniem. Poza paroma zgrzytami, o których niżej.
Mastodon – negatywy
Niestety, porównując z Twitterem widać braki w funkcjonalnościach. Można followować[2] ludzi ale… już nie hashtagi. Follow użytkownika z innej instancji nie jest intuicyjny. Przynajmniej przez przeglądarkę. Ewentualnie są bugi. Objawia się to tym, że po wejściu na profil ofiary zawsze aktywny jest przycisk follow. Nawet, jeśli już obserwujemy osobę.
Wiele instancji daje się we znaki także gdy chcemy poznać obserwujących dane konto. Nie jest to proste ani dostępne w zasięgu jednego kliknięcia. Tusky w ogóle pokazuje chyba tylko followersów z naszej instancji i nie ma możliwości podejrzenia pozostałych. Przynajmniej ja nie znalazłem, a patrzyłem w ustawieniach, czy nie mam czegoś wyłączonego. Z kolei Mastodon przez WWW wyświetla komunikat:
Followers from other servers are not displayed. Browse more on the original profile
Czyli da się, choć wymaga dodatkowego kliknięcia. Porównując z rozwiązaniami scentralizowanymi – średnie.
Edycja posta w Diasporze jest wygodniejsza. Po przyzwyczajeniu i zapamiętaniu podstaw składni, Markdown jednak robi robotę, szczególnie na mobilkach, gdzie nie mamy wygodnego dostępu do klawisza ctrl. Mastodon tego nie ma – po prostu wpisuje się tekst. W 99% niekrytyczne.
Kolejna sprawa jest poważniejsza. Rozproszenie powoduje, że w przypadku zamieszczenia linka na przez popularne konto, następuje wiele pobrań przez wszystkie serwery obserwujących daną osobę, w celu wygenerowania podglądu. Taki DDoS przez pobieranie podglądu strony. Efekt można zobaczyć w wątku, z którego dowiedziałem się o sprawie. Było zgłoszone jako issue na GitHubie, ale nie zostało rozwiązane. I nie wiem czy zostanie, bo na szali jest wolność i autonomia działania instancji.
Największa wada w stosunku do „dużych” platform: mało ludzi, mało treści. O ile na Twitterze bez problemu jestem w stanie znaleźć kolejne kilka kont, których mógłbym chcieć followować, to na Mastodonie jest to wyzwanie. Może kwestia ilości kont, może kwestia architektury, a może jestem po prostu za krótko na tej platformie i z czasem się to zmieni? W każdym razie zauważam to i nie cieszy mnie.
Mastodon czyli wolność
No i na koniec coś co pewnie nie dotyczy całego Mastodona, ale akurat serwera, na którym mam konto i wydaje mi się śmiesznym ograniczeniem, jeśli chodzi o wolną platformę. Zasady serwera mówią, że nie wolno używać nienadzorowanych botów kopiujących z jednego miejsca na Mastodon i że nie wolno crosspostować z Twittera. Kierunkowo, bo w drugą stronę można. Zresztą jest to później wprost napisane:
Cross-posting from Mastodon to other platforms is fully permitted. Cross-posting into Mastodon from another platform is not permitted.
Nie przeszkadza mi to. Gdyby było inaczej mógłbym przecież założyć konto na swoim serwerze, albo postawić własny, nieprawdaż? Natomiast kojarzy się mocno z odpowiedzią Kalego na pytanie co to jest dobry uczynek? I rodzi pytania o kwestie wolności, możliwość działania na większą skalę i ogólnie przyszłość. Raczej przyszłość odległą, więc odpowiedzi nie wydają mi się w tej chwili zbyt istotne.
Podsumowanie
Mastodon przy odrobinie samozaparcia nadaje się do użytku. Koncepcja jest ciekawa, choć ma przed sobą kilka wyzwań. Zdecydowanie wymaga wygładzenia, jeśli chce móc konkurować z „dużymi” na masową skalę. Gdybym miał bawić się w przepowiadanie przyszłości, to jest spora szansa, że Mastodon wchłonie Diasporę. I bardzo mała, że w przeciągu najbliższych kilku lat stanie się zauważalną alternatywą dla Facebooka czy Twittera. Nawet, jeśli moda przetrwa.
Niemniej, u mnie zostanie. Prawdopodobnie właśnie pomału kanibalizując Diasporę.
[1] Jak wynika z wpisu, z kolei Szczeżuję do założenia Mastodona zainspirowałem ja, przy pomocy Diaspory. Rekurencja… [2] Przydałby się polski odpowiednik angielskiego follow. Niby jest śledzić, ale – podobnie jak obserwować – to pasywna obserwacja, z boku, bez aspektu podążania czyjąś ścieżką, popierania. [3] Jak widać na przykładzie tego wpisu, wtyczka nie zadziałała. Przyczyna nieznana i nawet nie wiem jak to debugować. UPDATE Po bliższym przyjrzeniu się opcjom, okazało się, że nie zaznaczyłem opcji „toot on mastodon” przy publikacji wpisu. O tyle bez sensu, że w opcjach wtyczki mam wybrane „autopost new posts”.