
Ludzie przypomnieli, że dziś BlogDay. Wiele lat nie zamieszczałem wpisów z tej okazji i… w sumie dziś też nie będzie takiego wpisu, przynajmniej nie w tradycyjnej, dotychczasowej formie. Tzn. niczego nie będę polecał do czytnika RSS. Zamiast tego może jak to blogowanie wygląda.
Koniec wakacji, nieco nostalgiczny nastrój, kiedyś to było. Czy faktycznie? Postanowiłem zrobić statystykę ilości wpisów zamieszczanych na tym blogu.
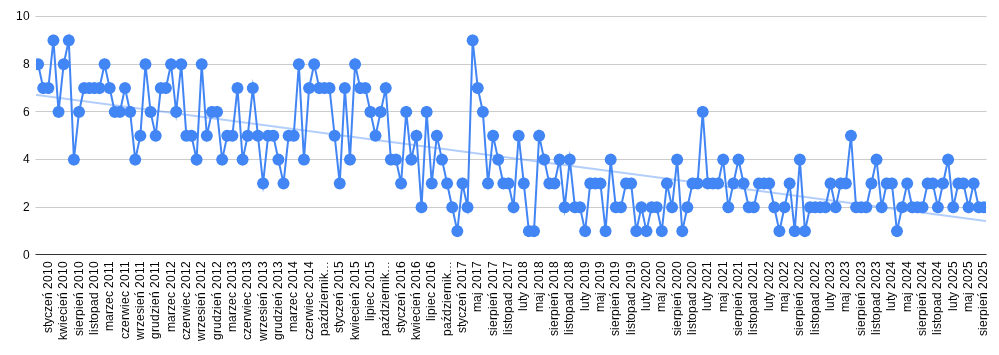
Nie ma niespodzianki, jest wyraźny spadek, co widać po linii trendu. Nie jest to do końca uczciwe, jeśli chodzi o moje pisanie, bo piszę nieco więcej, ale… gdzie indziej, na innych zasadach i tylko w trochę podobnej formie. Więc: na blogu – spadek.
A jak wygląda moje czytanie blogów? Cóż, pojawiają się jakieś nowe blogi, ale czytam raczej to, co wieki temu. Jak zajrzycie do starych polecanek z okazji BlogDay albo na Planetę Joggera, to znajdziecie większość blogów, które regularnie czytam. Część po prostu awansowała z mam w czytniku na regularnie zaglądam.
Zmienił się mój sposób czytania. Rzadziej korzystam z czytnika RSS do czytania blogów dla przyjemności, choć nadal pełni funkcję zakładek. Obecnie użytkowo pełni on bardziej funkcję agregatora newsów z portali. O nowych wpisach dowiaduję się raczej z Planety Joggera, social media lub po prostu wchodzę co jakiś czas na stronę. Nawiasem, jeśli piszecie bloga bloga, to warto dodać powiadomienia o nowych wpisach na socjale. RSSy trochę zdechły, mamy trochę natłok informacji, warto się dostosować, żeby dotrzeć do czytelników.
Co jeszcze? Pewnie pojawi się – który to już raz – stwierdzenie, że blogi umierają. To półprawda. Tzn. tak, część umiera. Ale także powstają nowe. I – podobnie jak kiedyś – wiele z nowych zniknie po paru latach. Tylko coraz bardziej mam wrażenie, że nic nowego i zawsze tak było.
Jeśli macie coś ciekawego do polecenia, zachęcam do napisania stosownych wpisów na swoich blogach.
