
Przypomniało mi się parę rzeczy związanych z dawno minioną pandemią, o której nikt nie pamięta. Część już zniknęła, reszta pewnie wkrótce zniknie, więc może dla pamięci, jak przy pomocy kłamstw, niedopowiedzeń i manipulacji nakłaniano do – słusznych swoją drogą, choć w inny sposób – szczepień.
Zanim jednak przejdę do konkretów, podlinkuję bardzo ciekawe rozliczenie pandemii, napisane cztery lata po jej wprowadzeniu, traktujące szerzej o błędach, które w jej trakcie popełniono i pokazujące, co można było zrobić lepiej. O szczepionkach też jest. Bardzo polecam lekturę przed kontynuacją. Chociaż nie ukrywam, że szkic wpisu powstał, zanim się dowiedziałem o tym artykule.
Mieliśmy – z tego co pamiętam rządowe – plakaty, na których było napisane, że 99% zgonów na COVID-19 dotyczy osób niezaszczepionych. Nie zrobiłem zdjęcia i żałuję, bo nie jestem w stanie znaleźć. Są ślady w sieci z opisem tych plaktatów, udało mi się znaleźć wypowiedź na stronie rządowej (screenshot poniżej) na podstawie której zdaje się był plakat, ale zdjęcia samego plakatu – nie.
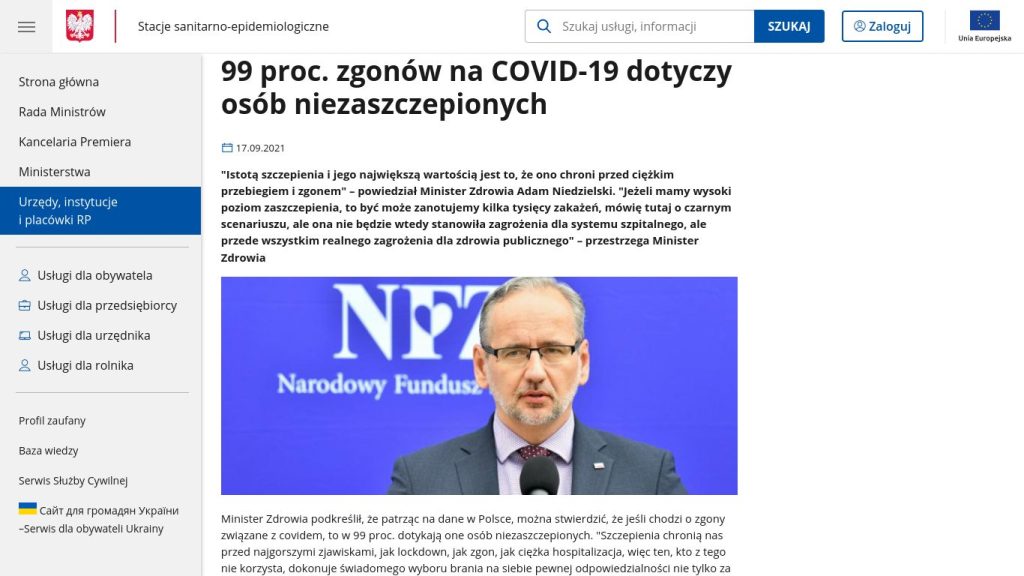
Kłamstwo? Manipulacja? Nie wiem. Oficjalne dane faktycznie pokazywały niższy odsetek zgonów wśród zaszczepionych, ale koło 99% to nie stało. Oczywiście nie można wykluczyć, że statystyka pochodzi z początkowego okresu szczepień, gdy po prostu osób zaszczepionych było bardzo mało. Tak czy inaczej – shady.
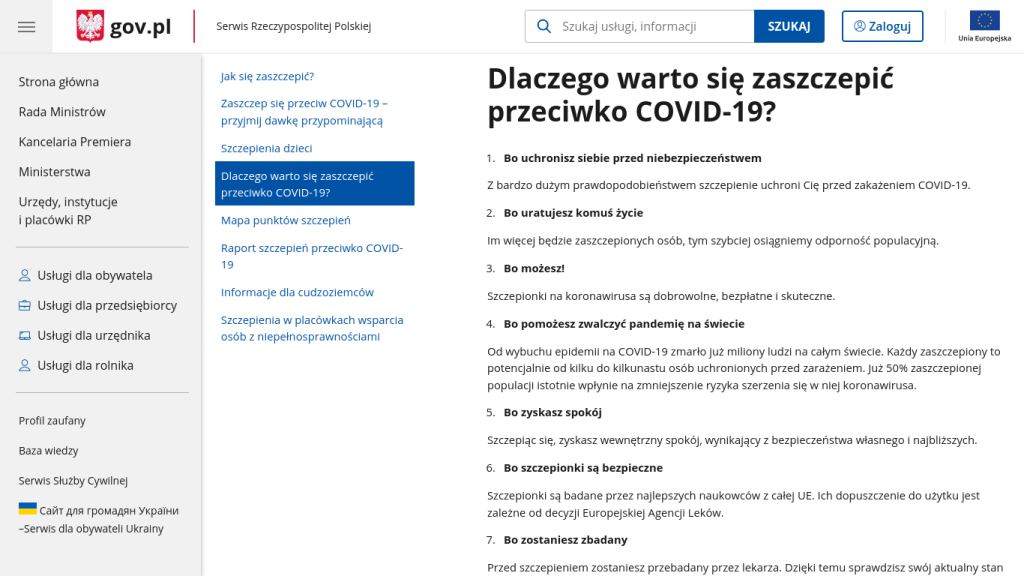
Szczepienia chronią przed zarażeniem, mówili. Znowu, patrząc na przytoczone statystyki, nie znajdujemy potwierdzenia. Twardych danych nie ma, ale wmawianie ludziom, że ochronią siebie, było manipulacją. Nie wierzycie, że tak było? Screenshot nieco niżej.
Namawiano też ludzi do szczepień przy pomocy argumentu Bo zostaniesz zbadany. Przed szczepieniem zostaniesz przebadany przez lekarza. Dzięki temu sprawdzisz swój aktualny stan zdrowia. Kto się szczepił ten wie, jak te „badania” wyglądały.
Kolejny argument, którym przekonywano do szczepień to Bo szczepionki są bezpieczne. Szczepionki są badane przez najlepszych naukowców z całej UE. Ich dopuszczenie do użytku jest zależne od decyzji Europejskiej Agencji Leków. Zdecydowanie manipulacja w przypadku szczepionek na COVID-19, były nowego typu i nie przeszły pełnych badań. Ale tak, „są badane” i „dopuszczenie jest zależne”. Tylko jakby było to bez związku w tym przypadku.
W ogóle kwestia ryzyk związanych ze szczepieniem jest pomijana, nie tylko w przypadku COVID-19. Statystycznie, szczepienie mocno opłaca się indywidualnie, o korzyściach dla całości społeczeństwa nie wspominając, ale nie jest w 100% bezpieczne. Podobnie jak żaden lek nie jest w 100% bezpieczny.
Mam przeczucie, że tego typu kłamstwa czy manipulacje to woda na młyn dla antyszczepionkowców i przynosi ostatecznie efekt odwrotny do zamierzonego. Wykazanie, że oficjalne źródła (rząd, koncerny medyczne, nauka) nie mówią prawdy, jest trywialne. I można już w rozmowie budować dowolną narrację powołując się na różności.
Myślę – i mam nadzieję – że to ostatni wpis o pandemii. Temat chodził mi po głowie, leżał w TODO i stwierdziłem, że warto zostawić ten ślad.