
Dawno nie było nic o macOS. Jest stabilnie, czyli korzystam i zbyt zadowolony nie jestem. Ostatnio zrobiłem aktualizację do 10.15.5, więc jest okazja do narzekania.
Przede wszystkim, robiłem aktualizację z 10.15.3, nie z 10.15.4, który był wydany pod koniec marca. Co też świadczy w jakiś sposób o tym, że te aktualizacje nie są wcale takie lekkie, łatwe i przyjemne, bo lubię mieć aktualny soft. Czynników było oczywiście więcej, taki drobiazg jak średnia wygoda by mnie nie powstrzymał. A to zespół opiekujący się systemami w firmie nie dał zielonego światła od razu, a to pandemia, więc trochę strach, że nie pójdzie i co wtedy, a to dyżury i wypada mieć sprzęt działający. Koniec końców, zdążyli wydać 10.15.5, nim zaktualizowałem.
Sama aktualizacja przypomniała mi, czemu nie jest to miły proces – stąd notka. 5 GB danych do pobrania, więc dużo. Wiedziałem, że to trwa, więc załączyłem i poszedłem precz. Gdy wróciłem, system marudził, że nie umie zamknąć programów. Znaczy głaszcz mnie użytkowniku, pozamykaj i try again. Zamknąłem kilka programów, dłuższą chwilę trwała walka z edytorem Atom. Bardzo nie chciał się zamknąć i koniec końców używałem force quit. Jeśli ktoś jest przyzwyczajony do podejścia linuksowego, gdzie system robi co mu się każe, bez szemrania i dodatkowego popychania – bardzo słabo to wygląda.
Jak już wszystko pozamykałem i w końcu się zrestartował, przypomniała mi się anegdotka o tym jak Windows liczy czas/postęp: ostatnie 5 min/5% trwa kwadrans/jedną trzecią czasu. Jak podczas pobierania wiało optymizmem, że będzie pół godziny, tak pół godziny to zbierał się po reboocie. To już nawet nie tylko Linux, ale nawet Windows jakoś szybciej sobie radzi z aktualizacjami.
Potem, po uruchomieniu, było z górki, za wyjątkiem jednego ostrzeżenia, które wyglądało tak:
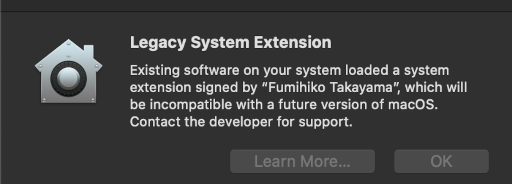
Existing software on your system loaded system extension signed by „Fumihiko Kakayama”, which will be incompatible with a future version of macOS. Contact the developer for support.
Zgadza się, nie jest napisane o jaki program chodzi. Za to jest imię i nazwisko developera, który podpisał rozszerzenie systemowe. Nie wiem jak czytelnicy, ale ja kojarzę jakiego softu używam, nie kto go jest developerem, a już o rozszerzeniach i osobach je podpisujących nie mam pojęcia. No ale ja truskawki cukrem… Odnośnika brak, w learn more również pustka.
W każdym razie szybkie wyszukanie ujawniło, że chodzi o Karabiner. I jestem trochę przerażony, bo bez tego softu macbook będzie dla mnie nieużywalny praktycznie. Przynajmniej w zakresie pisania z pl-znakami. Mam nadzieję, że poprawią lub będzie inna opcja na przemapowanie klawiszy[1].
Trochę jestem zdziwiony, że nie jest napisane o którą wersję chodzi. Dużą? Małą? Najbliższą? Którąś kolejną?
[1] UPDATE Po czasie okazało się, że można przemapować klawisze bez Karabiner Elements.