Tytułem wstępu: Google ma swoją chmurę, czyli Google Cloud Platform, a w ramach niej coś takiego jak free tier, czyli zasoby dostępne bez opłat[1]. Zasoby są niewielkie, dodatkowo podlegające pewnym ograniczeniom, raczej do zabawy. Ale do testów, nauki czy właśnie zabawy – idealne. Między innymi można mieć uruchomioną w ramach compute engine najsłabszą VMkę, czyli f1-micro.
Mail
Jeśli ktoś korzysta z GCP, to zapewne dostał już maila. Dla tych, co maila przeoczyli, krótkie podsumowanie. Od pierwszego sierpnia 2021 instancje e2-micro są bezpłatne (w określonej ilości czasu), natomiast od pierwszego września instancje f1-micro będą płatne. Regiony pozostają bez zmian. Instrukcja zmiany linkowana w mailu dostępna jest tu.
To różne platformy, więc ciężko porównać dokładnie, ale: f1-micro to 0.2 VCPU i 0.6 GB RAM w cenie $0.0076 (us-central1) e2-micro to 0.25 VCPU i 1 GB RAM w cenie $0.008376 (us-central1) Dodatkowo w przypadku e2-micro możliwy jest burst do 2 VCPU.
Google pisze[2]:
As we improve the experience of the Free Tier, we will be introducing the E2-micro VM, which is a part of a second generation VM family.
Wydajność
W przypadku RAM zysk jest oczywisty, natomiast w przypadku CPU – niekoniecznie. Wiele zależy od tego, na jakiej platformie CPU znajduje się obecnie VMka, i na jakiej wyląduje po przeniesieniu. Tabela platform CPU dla serii N1 i E2 jest dość skomplikowana. Jednak patrząc na base frequency, przeciętnie powinno być szybciej.
I jeszcze wynik cat /proc/cpuinfo z mojej instancji f1-micro:
processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 63 model name : Intel(R) Xeon(R) CPU @ 2.30GHz stepping : 0 microcode : 0x1 cpu MHz : 2299.998 cache size : 46080 KB physical id : 0 siblings : 1 core id : 0 cpu cores : 1 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 13 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology n$ bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs bogomips : 4599.99 clflush size : 64
Jak się zmigruję to uzupełnię wpis, co dostałem po migracji i jak wrażenia.
Migracja
Wczoraj zmigrowałem maszynę na e2-micro. Migracja błyskawiczna i bezproblemowa. Zgodnie z instrukcją zatrzymać instancję, wyedytować typ, zapisać zmianę, uruchomić maszynę.
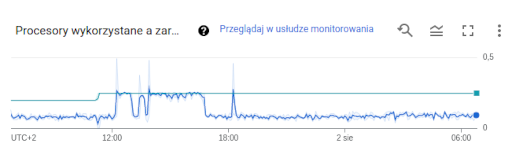
Po migracji dostałem dokładnie ten sam procesor. Tyle, że teraz cat /proc/cpuinfo pokazuje dwa. Jeśli chodzi o osiągi i wydajność w praktyce, to najlepiej widać to na obrazku.
Wykorzystanie CPU na f1-micro vs e2-micro
Migracja chwilę przed 12:00, później wzrost obciążenia spowodowany porządkami, chwilę po 18:00 koniec ostatnich ręcznych prac. Jak widać, główny zysk wynika ze wzrostu mnożnika z 0.2 do 0.25 VCPU. Ponieważ przydział jest dynamiczny, procesy jednowątkowe także skorzystają na zmianie parametrów.
Podsumowując, warto migrować, bo e2-micro w stosunku do f1-micro oferuje 66% więcej RAM i 25% więcej CPU.
[1] Wymagane jest podpięcie karty debetowej, a po przekroczeniu puli darmowych zasobów jest automatycznie naliczana opłata za przekroczoną część. [2] Nawiasem, wysłaniem tego maila Google Cloud Platform zdobyło u mnie sporo punktów sympatii. Mogli przecież np. zamieścić info o zmianie cenników free tier na blogu i billować nieuważnych, albo wysłać suchego maila o zmianach w cenniku. Wiele firm tak właśnie by postąpiło. A tu osobne, czytelne powiadomienie, z instrukcją migracji. Miło.
Jednym z powodów dla których umieściłem CAPTCHA[1] na blogu była chęć zmniejszenia ilości spamu w komentarzach. Dokładniej, ilości spamu do moderacji, bo i tak wszystkie komentarze przechodzą tu przez ręczną moderację, nim pojawią się na blogu.
Na początek drobne statystyki. WordPress pokazuje równe 230 komentarzy oznaczonych jako spam. Najstarszy z 24.10.2018. Do wczoraj[2] daje to 909 dni, czyli średnio ok. jednego spamu na cztery dni. Nie jest to dokładna statystyka, część mogłem kiedyś usunąć, zamiast oznaczyć jako spam. Zjawisko nie było też stałe w czasie. Mam wrażenie, że ostatnio się nasilało. Na pewno luty, marzec i kwiecień tego roku to większe ilości. Z kolei styczeń to tylko pięć spamów. Jeśli miałbym oceniać na oko, to stawiałbym bardziej średnio na spam co drugi dzień. Do przeżycia.
Rodzajów spamu też było kilka i pojawiał się falami. Były i polskie pseudokomentarze typu „ciekawy wpis” z typowym SEO linkiem, i komentarze pisane cyrylicą. Dominowały jednak anglojęzyczne reklamy środków viagropodobnych. Regularności we wpisach pod którymi zamieszczano komentarze praktycznie żadnej. Podobnie z IP wykorzystywanymi do wysyłki spamu. Na oko raczej stare wpisy, z różnych kategorii. 230 to nie jest duża próbka do analizy, ale może kiedyś zrobię statystyki.
Skoro spamerzy obchodzili reCAPTCHA, stwierdziłem, że to dobra okazja do wypróbowania alternatywy, o której ostatnio trochę było słychać. Chodzi o serwis hCaptcha. Rejestracja niezbyt gładka. A to mail na Onecie został uznany za nieprawdziwy adres email, a to były problemy z dostarczeniem maila z linkiem aktywacyjnym na inną skrzynkę. W końcu odnalazł się on w folderze spam.
Po aktywacji jest już z górki. Użyłem pluginu hCaptcha for WordPress, który pozwala na określenie, gdzie ma być serwowana CAPTCHA. Podajemy klucze API i… już. Przyznam, że kusiło mnie przez moment wypróbowanie używania obu pluginów jednocześnie. Szybko porzuciłem tę myśl. CAPTCHA jednak i jest nieco upierdliwym mechanizmem, i dokłada trochę objętości do wielkości strony.
No właśnie. W porównaniu z pierwotną wersją strona jest obecnie nieco cięższa. I główna, i strony poszczególnych wpisów. Dramatu nie ma, nad główną jeszcze popracuję, ale z kronikarskiego obowiązku odnotowuję.
Co dalej? Ano czekam na feedback od użytkowników jak się nowa CAPTCHA podoba. A jeśli spamer wróci z tego samego IP, to dostanie w łeb. Tarpitem. Jeśli i to nie pomoże, poszukam innych pluginów WordPress stworzonych, by zwalczać spam. No i przede wszystkim będę obserwował ilość spamu przychodzącego do moderacji.
[1] Dokładnie reCAPTCHA wraz z pluginem Advanced noCaptcha & invisible Captcha. Tutaj znajdziesz więcej o wykorzystywanych na tym blogu czy polecanych pluginach do WordPressa. [2] Jeśli ktoś zada sobie trud policzenia, to wyjdzie nieścisłość matematyczna. I można policzyć ile dni wpis leżakował jako szkic. [3] Tak, to akurat przeciwko hCaptcha, ale miałem pod ręką linka. Dla reCaptcha pewnie też coś analogicznego istnieje.
Za sprawą zbanowania Donalda Trumpa na Twitterze głośno zrobiło się w temacie wolności wypowiedzi w social media. Także odnośnie braku regulacji prawnych dotyczących social media i centralizacji usług. Zaczęły powstawać „wolne” alternatywy. Ponieważ zdarzyło mi się już tłumaczyć w paru miejscach moje stanowisko, pora na wpis.
Źródło: wygenerowane za pomocą https://thumbnail.ai/
Problem
W czym w ogóle problem? Przecież nigdy nie było tak, że każdy może skorzystać ze środków masowego przekazu. O treściach zamieszczanych w prasie decydował redaktor, podobnie w przypadku telewizji czy radio. Każdy mógł zadzwonić, ale na antenę nie dostawał się każdy. Dodatkowo obszar był uregulowany przez prawo prasowe. Choćby prawo do zamieszczenia sprostowania. I polemiki ze sprostowaniem. Nawet jeśli była np. w zakładzie pracy gablota na ogłoszenia, to miała ona właściciela. I mógł on nieodpowiadające mu treści po prostu usunąć. Albo zamknąć ją na kluczyk.
Sytuacja się zmieniła. Nie mamy już typowego broadcastingu, gdzie pojedyncza osoba rozgłasza treści, czyli jest nadawcą, a pozostali są odbiorcami. Obecny model zdemokratyzował bycie nadawcą. Każdy może publikować treści, które są dostępne dla wszystkich. Ale nie to jest najważniejszą zmianą. Już wcześniej każdy mógł uruchomić swoje radio, czasopismo czy postawić własną gablotę z ogłoszeniami. Oczywiście o ile miał odpowiednie środki i kompetencje. Pieniądze i znajomość prawa, powiedzmy.
Najważniejsze zmianą jest coś innego. W sumie nie zmianą, a zmianami. Po pierwsze, social media sprawiły, że publikacja treści dla wszystkich nie wymaga istotnych nakładów ze strony nadawcy. Nie są potrzebne ani specjalne środki, ani kompetencje, by zacząć przekaz do wszystkich w kraju i na świecie. O ile będą chętni, by nas słuchać.
Prawa człowieka
Po drugie i najważniejsze, ten sposób komunikacji stał się powszechny i dominujący. Odebranie komuś możliwości publikowania poglądów w ten sposób jest pewnego rodzaju wykluczeniem społecznym. Trochę tak, jakby kiedyś zabronić komuś rozmawiać w szkole czy zakładzie pracy. Dotyczy to zarówno w życia prywatnego, jak i – w niektórych przypadkach – zawodowego. W przypadku niektórych istotna część życia zawodowego toczy się na Linkedin czy GitHub[1] . Wyobrażacie sobie rekrutera pracującego w branży IT z wykluczonym korzystaniem z Linkedin? Ja nie.
Dlatego coraz częściej pojawiają się głosy, że prawo do internetu to podstawowe prawo człowieka. W badaniu w roku 2010 77% ankietowanych spośród 27 tys. osób z 26 krajów Europy określiło, dostęp do internetu jako podstawowe prawo człowieka[2]. Wydaje mi się, że można w tym momencie utożsamić internet z social media.
Centralizacja i struktura serwisów social media
Oba przytoczone wyżej serwisy są centralne. Podobnie jak Twitter czy Facebook. W tym momencie pojawia się pytanie o wolność i regulacje prawne. W kontekście wolności słowa i prawa człowieka. Aby dokładniej zobaczyć w czym problem, trzeba przeanalizować strukturę władzy w serwisach social media. Typowo wygląda ona następująco:
Właściciel serwisu – ten, który ma środki. Pieniądze, prawa do domeny, przetwarzania danych użytkowników itp.
Dostawcy infrastruktury – podmioty zapewniające łączność i hosting. Firmy zewnętrzne, ale w większości przypadków niezbędne dla funkcjonowania.
Administrator serwisu – osoba z wiedzą techniczną, umiejąca utrzymać serwis w działaniu. Zarządzanie infrastrukturą, konfiguracja oprogramowania. Może być po prostu pracownikiem na usługach właściciela.
Moderatorzy serwisu – osoby mogące usuwać treści lub użytkowników. Niekoniecznie w kontekście całego serwisu, mogą zarządzać wydzieloną częścią (np. grupą na FB). Mogą być pracownikami na usługach właściciela lub rekrutować się z użytkowników.
Użytkownicy – osoby korzystające z serwisu. Uczestnicy komunikacji. Nadawcy i odbiorcy treści.
Oczywiście funkcje mogą się łączyć. Istotny jest tu fakt, że każda instancja wyższa ma środki techniczne, by ograniczać w dowolny sposób wszystkie instancje niższe. Także eliminując zupełnie ich dostęp do serwisu.
Nawiasem, zagadnienie jest szersze. Temat nie dotyczy tylko typowych social media i tylko o ograniczanie dostępu. Gdy Google, Agora czy Wirtualna Polska mówi, że zamyka serwis to użytkownicy nie mają nic do powiedzenia. Nie muszą nawet dostać możliwości pobrania pełnych treści w formacie zdatnym do łatwego przetworzenia maszynowo. Podobnie z blokowaniem dostępu do serwisów, w szczególności do publikacji treści.
Centralizacja
Nie jest to temat nowy, dominująca rola gigantów social media została dostrzeżona już dawno. Pojawiły się rozwiązania alternatywne, oparte o fediwersum. Czyli osobne, niezależne serwisy, ale dające możliwość interakcji między użytkownikami różnych instancji.
Na pierwszy rzut oka fediwersum wydaje się to rozwiązaniem problemu centralizacji. Ale czy jest nim faktycznie? Uważam, że nie. Gwarancja wolności w tym przypadku opiera się na tym, że użytkownik może pójść na inną instancję. Albo, w skrajnym przypadku, uruchomić własną.
Niestety, uruchomienie własnej instancji leży poza kompetencjami większości użytkowników. Uruchomienie to kompetencje administratora, a istniejące rozwiązania wymagają specjalistycznej wiedzy. Nie są może trudne dla ludzi z IT, ale świat nie składa się ani wyłącznie, ani nawet w większości z ludzi z IT.
Co gorsza, nawet uruchomienie własnej instancji nie gwarantuje, że ludzie z innych będą mieli dostęp do naszych treści. Wymiana danych między instancjami jest bowiem opcjonalna, dobrowolna i może zostać zablokowana. Na wielu poziomach, od konfiguracji instancji, przez filtrowanie pakietów sieciowych. Oczywiście takie rozwiązanie zmniejsza centralizację, ale nie eliminuje źródła problemu.
Rozwiązanie
O rozwiązaniu problemu centralizacji możemy mówić, gdy dowolnych dwóch użytkowników, którzy wyrażą taką wolę, będzie się mogło komunikować ze sobą. Niezależnie od decyzji innych osób i przynależności do serwerów. Fediwersum takiej gwarancji niestety nie daje[3]. I nie znam rozwiązania, które coś takiego oferuje.
Technicznie widziałbym to jako oddanie pełnej decyzyjności o odbieranych informacjach w ręce użytkowników końcowych. Czyli protokół pozwalający na wymianę informacji ze wszystkimi, nie dopuszczający cenzurowania. I prosta aplikacja, zastępująca serwis, używalna dla zwykłych użytkowników, pozwalająca na korzystanie (subskrybcję tematów, tagów, użytkowników, nadawanie, odbieranie wiadomości) przy pomocy tego protokołu. Z możliwością filtrowania użytkowników, tagów, tematów zarządzaną na poziomie użytkownika.
Wydaje mi się, że blisko tego modelu – pomijając aspekt centralnych serwerów – byliśmy w czasach NNTP. Użytkownik miał swój czytnik, swoje subskrybcje i filtry. Pobierał co chciał, odsiewał co chciał. Korzystanie z czytnika nie było wiele trudniejsze, niż obsługa email. Oczywiście wtedy obsługa email nie była powszechna, a i UX aplikacji był inny.
Gdyby dołożyć do tego „niecenzurowalny”, rozproszony protokół wymiany danych, mielibyśmy coś, co wydaje mi się rozwiązaniem. Nie znam szczegółów rozwiązania, ale wydaje mi się, że IPFS miałby szanse spełnić te wymagania. Tym bardziej, że zdobywa popularność – wchodzi do przeglądarek, na przykład jest już oficjalnie w Brave.
[1] Tak, uważam GH za pewnego rodzaju social media. Nie typowe socjalne, bardziej techniczne, dla wąskiej grupy, ze specyficznym elementem socjalnym, ale nadal twór tego typu. Na zasadzie: zwykli ludzie pokazują fotki i komentują je, programiści pokazują kod, wysyłają pull requesty. Nie jest to oczywiście dokładna analogia. [2] 50% odpowiedzi tak, kolejne 27% raczej tak. [3] Widzę, że PeerTube jest częścią fediwersum. I wydaje mi się odporne na cenzurowanie. Może więc być tak, że problemem są implementacje. W każdym razie pisząc o fediwersum mam tu na myśli implementacje w stylu Diaspora, Mastodon, StatusNet.